Databricks is a cloud-based platform built on Apache Spark, providing a unified, open analytics and AI platform for building, deploying, and managing enterprise-grade data, analytics, and machine learning solutions at scale.
Unified Workspace
A single platform for data preparation, real-time analysis, and machine learning, enabling seamless collaboration between data engineers, scientists, and analysts.
Scalability & Flexibility
Designed to efficiently handle massive datasets, utilizing auto-scaling clusters and supporting multiple languages (Python, SQL, R, and Scala) for various workloads.
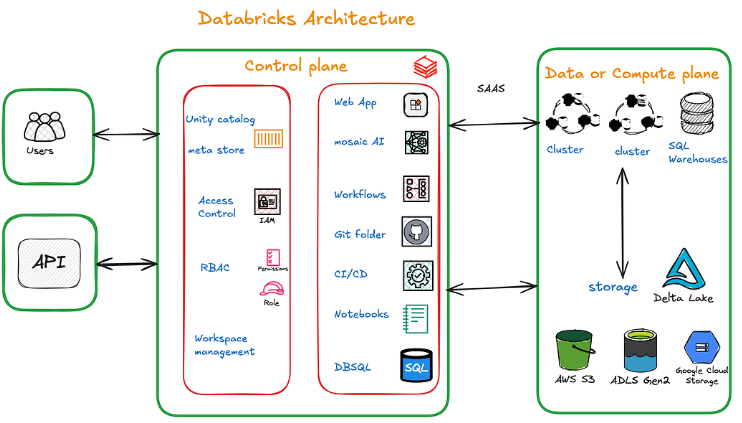
Architecture Summary
Databricks follows a secure two-layer architecture: the Control Plane (managed by Databricks, handling governance and scheduling) and the Compute Plane (hosted in the customer's cloud environment, handling processing and storage).
Data Lakehouse Architecture
Combines the reliability of data warehouses with the flexibility of data lakes, serving as a single, governed source of truth (built on Delta Lake).
ETL & Data Engineering
Simplifies ingestion, transformation, and orchestration of data pipelines using tools like Auto Loader and Lakeflow Declarative Pipelines.
Machine Learning & AI
Built-in ML runtime with MLflow, supporting LLM fine-tuning and integration with advanced frameworks for rapid model deployment.
Data Governance & Security
Centralized governance with Unity Catalog for fine-grained access control, lineage tracking, and secure sharing via Delta Sharing.
Streaming & Real-Time Analytics
Leveraging Structured Streaming for processing incremental and live data feeds, enabling real-time insights.
Use Cases
Ideal for scalable ETL, ML Model Training/Deployment, Real-Time Analytics, and multi-cloud environments.
 -->
-->